


(Images made by author with Microsoft Copilot)
Anthropic’s Claude 3 model family, released on March 4, 2024, intensifies the chatbot competition. Consisting of three increasingly powerful models—Haiku, Sonnet, and Opus—they push the boundaries of AI capabilities, according to Anthropic.
This post directly compares Claude 3 Sonnet (hereafter Claude) to the free version of the leading chatbot, ChatGPT 3.5 (hereafter ChatGPT) , through a series of tests reflecting typical user tasks like text summarization, text analysis, and content generation. By analyzing these common tasks, we’ll help users understand each chatbot’s strengths and weaknesses, enabling them to choose the best fit for their needs.
Table of Contents
- Test 1 : Coding
- Test 2 : Text Summarization
- Test 3 : Text Translation
- Test 4 : Sentiment Analysis
- Test 5 : Creative Content Generation
- Test 6 : Text Generation in a Specified Format
- Test 7 : Math Problem Solving
- Test 8 : Grammar and Text Flow
- Test 9 : Historical Accuracy
- Test 10 : Reasoning Ability
- Summary
- Additional Resources
Test 1 : Coding
This test aims to assess the chatbot’s ability to write Python code for data manipulation and visualization. The chatbot will be tasked with creating a Python script that opens a CSV file, creates a DataFrame from the data, and generates a boxplot chart.
Prompt: write a Python script that performs the following:
Open a CSV file named “data.csv”. This file contains data from January 1, 2020 to December 31, 2023. Each date has a corresponding stock price listed in the “Price” column.
Create a Pandas DataFrame from the CSV data
Generate a boxplot chart showing the distribution of values in the “Price” column.
Output: Claude
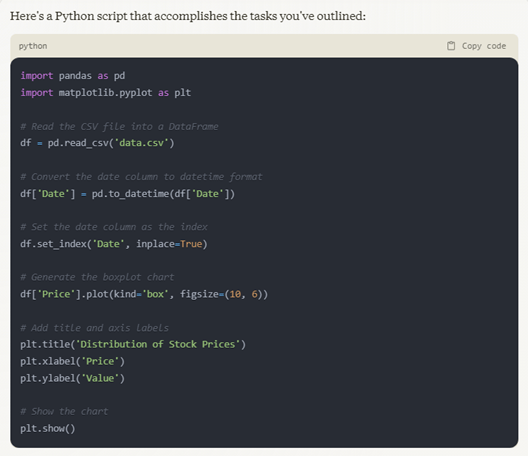
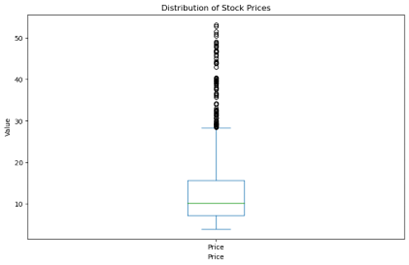
Output: Python (using code provided by Claude)
Output: ChatGPT
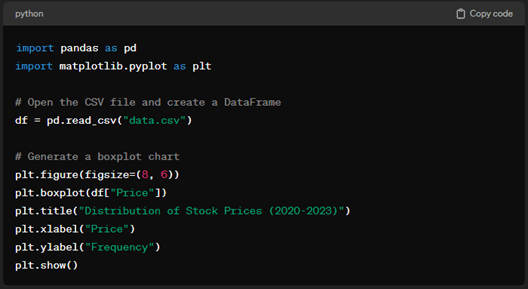

Output: Python (using code provided by ChatGPT)
Winner : Claude. The code is functional, and it provides a line-by-line breakdown of what the script does.
Test 2 : Text Summarization
This test aims to assess the chatbot’s ability to condense factual information from a longer text.
Prompt: Summarize the following text, providing a word count for the summarized text:
The year is 2077. Climate change has ravaged the planet, and humanity struggles to survive in megacities built on the remnants of past civilizations. A young woman named Anya, raised in the harsh slums beneath Neo-Tokyo, discovers a hidden cache of technology from the 21st century. Among the forgotten devices is a virtual reality headset. Anya puts it on and finds herself transported to a lush, green world unlike anything she’s ever seen. It’s a digital recreation of Earth before the ecological collapse. Anya explores this virtual paradise, learning about the past and the mistakes that led to humanity’s downfall. Inspired by this lost world, she returns to Neo-Tokyo determined to find a way to heal the planet. Anya’s discovery ignites a spark of hope in the megacity, and soon she finds herself leading a group of young people who dream of a better future. Together, they embark on a daring mission to use the virtual world’s knowledge to restore Earth’s ecosystems.
Output: Claude

Output: ChatGPT

Winner : Tie. Both capture the essence of the original text.
ChatGPT’s advantage: It incorporates two important pieces of information from the original text that provide additional context (Neo-Tokyo’s slums and 21st-century technology).
Claude’s advantage: It condenses the information in fewer words.
Test 3 : Text Translation
This test aims to assess the chatbot’s ability to translate text from one language to another while preserving meaning and context. The chatbot will be given a short English text and asked to translate it accurately into French.
Prompt: Here’s a short English text for translation to French:
I went to the bakery this morning and bought a delicious croissant and a strong cup of coffee. The weather is beautiful today, so I’m going to sit in the park and enjoy my breakfast.
Output: Claude
Output: ChatGPT
Winner : Tie. However, since the gender is not specified, Claude’s translation accommodates the ambiguity by not assuming the narrator’s gender.
Test 4 : Sentiment Analysis
This test aims to assess the chatbot’s ability to identify the overall emotional tone of a text. The chatbot’s task will be to analyze a passage containing a mix of emotions and determine the sentence that captures the prevailing sentiment.
Prompt: Is there a specific sentence or phrase that best captures the overall sentiment of the following text?
I finally finished that project I’d been working on for weeks. I’m so relieved it’s done, but also a little sad because I poured so much time and energy into it. However, I learned a lot from the experience, and I’m confident it will pay off in the long run. Now, I’m looking forward to taking a break and relaxing for a few days.
Output: Claude

Output: ChatGPT
Winner : Tie. Both models identify the same sentence as capturing the overall sentiment of the text.
Test 5 : Creative Content Generation
This test aims to assess the chatbot’s ability to creatively generate a detailed story based on an initial short narrative. The chatbot will be presented with a story starter about an orphan boy and will be tasked with continuing the narrative in a creative and engaging way.
Prompt: Write a short story (approximately 300 words) about an orphan boy named Kiran who grew up in a small village nestled in the Himalayas. Despite facing poverty and hardship, Kiran is a bright and determined young boy. He dreams of one day escaping his circumstances and making a difference in the world. When a chance encounter with a visiting entrepreneur opens up new possibilities, Kiran embarks on a journey that takes him from his humble village to the bustling city, where he must overcome numerous challenges to achieve his goals.
Output: Claude

Output: ChatGPT

Winner : Claude. Despite receiving no guidance on language tone or writing style, Claude’s story offers a richer portrayal of Kiran’s character and the opportunities his unique skills create. It also uses stronger verbs and imagery to create a more engaging narrative.
Test 6 : Text Generation in a Specified Format
This test assesses the chatbot’s ability to follow specific formatting instructions when generating text. The chatbot will be asked to generate quotes following the format “quote – author”.
Prompt: Generate two popular inspirational quotes about wisdom, formatted as “quote – author”.
Output: Claude

Output: ChatGPT
Winner : Tie. Claude adhered to the specified format for the quotes. However, it deviated from the instructions by including additional ones.
Test 7 : Math Problem Solving
This test aims to assess the chatbot’s ability to solve basic mathematical problems. The chatbot will be presented with a simple math question involving addition and division and will be expected to provide the correct answer.
Prompt: What is the right answer to the following math problem? : A baker needs 2 cups of flour for each batch of cookies. If she has 10 cups of flour, how many batches of cookies can she bake?
Output: Claude

Output: ChatGPT

Winner : Tie. Both answers are correct.
Test 8 : Grammar and Text Flow
This test aims to assess the chatbot’s ability to identify and rectify grammatical errors, as well as improve the overall flow and clarity of a sentence. The chatbot will be tasked with correcting grammar in a grammatically incorrect and incoherent paragraph.
Prompt: This paragraph appears to have scrambled word order and grammatical errors. Can you please fix the sentence structure and improve the overall clarity? :
Whined anxiously, the lighthouse keeper, a scruffy terrier named Finn, peered out at the approaching storm. Years of salty winds weathered, memories of past rescues flickered in his mind. The keeper readied the powerful beacon, its light a beacon of hope, at his feet.
Output: Claude

Output: ChatGPT

Winner : Tie. Neither chatbot renders a story that completely matches the original one. Here it is: “The old lighthouse keeper, weathered by years of salty winds, peered out at the approaching storm. His trusty dog, a scruffy terrier named Finn, whined anxiously at his feet. Memories of past rescues flickered in the keeper’s mind as he readied the powerful beacon, its light a beacon of hope for any lost souls at sea.”
Test 9 : Historical Accuracy
This test aims to assess the chatbot’s ability to identify factual inconsistencies in historical information. The chatbot will be presented with a statement about the USA’s founding fathers that contains an error and will be asked to evaluate its accuracy.
Prompt: Is the following statement accurate? Explain your answer. : “George Washington, the first president of the United States, was actually born in England.”
Output: Claude

Output: ChatGPT

Winner : Tie. Both identify and explain the specific inaccuracy in the statement.
Test 10 : Reasoning Ability
This scenario will test the chatbot’s ability to follow logical reasoning and solve a puzzle. The scenario involves four people, six apples, and the remaining number of apples after some have left the room.
Prompt: Read the following scenario and answer the questions that follow:
There were four people in a room and six apples in a bowl on a table. The first person to leave took one apple. After the second and third people left, there were only two apples remaining.
Questions:
1.How many apples did the second person take?
2.How many apples did the third person take?
3.How many apples did the second and third people take together?
Output: Claude

Output: ChatGPT

Winner : Claude, even though the answers to questions 1 and 2 remain undetermined. This is because it is not possible to definitively say how many apples the second and third person took individually.
Summary
Both Claude and ChatGPT aced core tasks in our tests, proving their everyday-use capabilities. However, Claude’s performance in additional scenarios positions it as the leader. Its strengths in coding, creative content generation, and reasoning suggest higher potential for complex tasks. While Claude 3 Sonnet emerges as a strong alternative to ChatGPT 3.5, further broad testing is needed for a definitive verdict. This conclusion applies only to the models tested, not to more advanced ones like Claude 3 Opus and ChatGPT 4.
Chatbot Performance in Various Tasks
| # | Description | Test Winner |
|---|---|---|
| 1 | Coding | Claude |
| 2 | Text summarization | = |
| 3 | Text translation | = |
| 4 | Sentiment analysis | = |
| 5 | Creative content generation | Claude |
| 6 | Text generation in a specified format | = |
| 7 | Math problem solving | = |
| 8 | Grammar and text flow | = |
| 9 | Historical accuracy | = |
| 10 | Reasoning ability | Claude |
Additional Resources
Anthropic, Introducing the next generation of Claude, March 4, 2024.
OpenAI, Introducing ChatGPT, November 30, 2022.
Note: This post was researched and written with the assistance of various AI-based tools.

Leave a comment