


(Images created with the assistance of AI image generation tools)
DeepSeek is making waves in the AI world by developing powerful and efficient AI models. DeepSeek’s approach combines clever architectural designs and training techniques. This post explores key concepts to provide a better understanding of how DeepSeek’s models learn, reason, and adapt. These include Mixture of Experts (MoE), Reinforcement Learning (RL), Chain-of-Thought prompting, model distillation, and test-time scaling.
Table of Contents
Mixture of Experts (MoE): Smarter, Not Just Bigger
Imagine a team where each member is an expert in a specific area. Instead of everyone trying to handle every task, a “router” directs each task to the most qualified expert. That’s the basic idea behind Mixture of Experts (MoE), a type of neural network architecture.
Traditional neural networks use all their “brainpower” (parameters) for every task. MoE, however, uses specialized sub-networks (“experts”) and a routing system. This means only the relevant parts of the network are activated for a given input, making the process much more efficient.
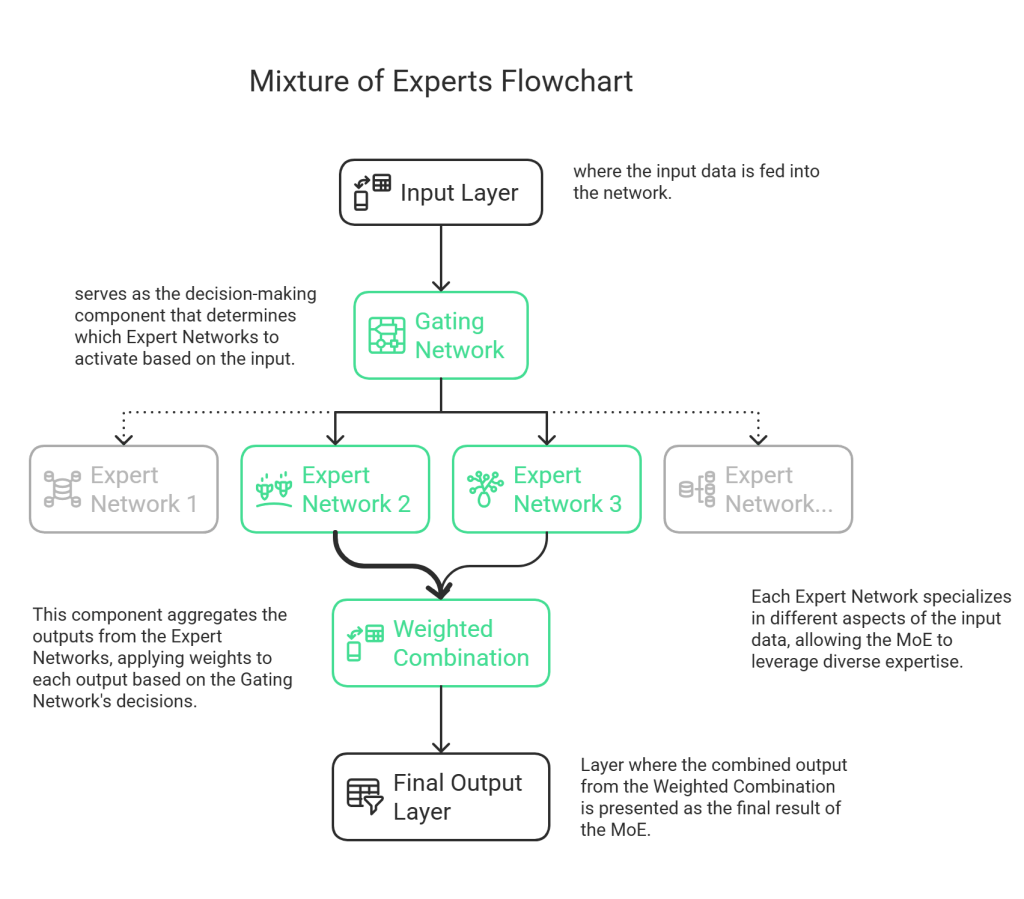
AI Talks Blog. Diagram generated using Napkin AI (napkin.ai)
DeepSeek’s models, such as DeepSeek-R1 and DeepSeek-R1-Zero, utilize the Mixture of Experts (MoE) architecture. These models have a massive capacity—approximately 671 billion parameters—but intelligently activate only a portion, roughly 37 billion parameters per token, for a typical task. This selective activation allows the models to achieve impressive performance without excessive computational costs. The efficiency of MoE challenges the notion that bigger AI models are always better, demonstrating that strategic resource allocation is crucial.
Reinforcement Learning (RL): Learning by Doing
Reinforcement Learning (RL) is like teaching a dog a new trick. You reward good behavior and discourage bad behavior. In RL, AI models learn by interacting with an environment and receiving rewards or penalties for their actions.
DeepSeek-R1’s capabilities are developed through a multi-stage training process that incorporates reinforcement learning (RL) to enhance both reasoning skills and alignment with human preferences. This process unfolds in distinct stages:
Stage 1: Initial Fine-tuning (Cold Start): The model starts with a small, carefully chosen dataset to establish a solid base. This “cold-start” approach prevents instability later in training.
Stage 2: Focused Reasoning Training: The model then focuses on RL training specifically designed to improve reasoning in areas like coding, math, science, and logic.
Stage 3: Supervised Fine-tuning: The model is further trained on a mix of high-quality data from the previous RL stage and other data covering writing, role-playing, and general tasks. This makes the model more versatile.
Stage 4: Final RL Refinement: A final RL stage aligns the model with human preferences, making it more helpful and safer, while continuing to refine its reasoning.
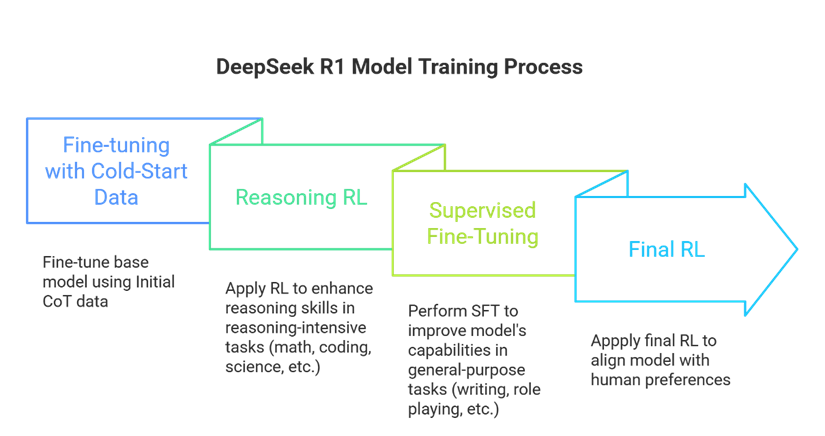
AI Talks Blog. Diagram generated using Napkin AI (napkin.ai)
Through RL, models in the DeepSeek-R1 series become much better at reasoning and exhibit more sophisticated behavior.
Chain-of-Thought (CoT): Thinking Step-by-Step
Chain-of-Thought (CoT) is a technique that dramatically improves the reasoning abilities of AI models by guiding them to break down complex problems into smaller, more manageable steps.
Consider the following question: If a train leaves New York at 8:00 AM traveling at 60 mph, and another train leaves Chicago at 9:00 AM traveling at 80 mph, when will they meet (assuming a straight track and a distance of 800 miles)?
Instead of allowing the model to generate a direct answer, a CoT approach guides it through a series of intermediate reasoning steps. An example of this is the prompt: ‘Let’s think step by step. First, calculate the distance the first train travels in one hour. Then, find the relative speed of the two trains. Finally, calculate…‘
The DeepSeek R1-series models don’t merely respond to CoT prompting; they learn to generate these intermediate reasoning steps internally through RL. During training, the models are explicitly rewarded for producing logically sound reasoning steps before providing the final answer. This is facilitated by a training template, as shown below for DeepSeel-R1-Zero, which uses <think> and <answer> tags to separate the reasoning process from the solution.

source : DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via
Reinforcement Learning
By internalizing CoT through reinforcement learning, the models perform significantly better on tasks requiring careful, logical progression. Furthermore, this approach makes their reasoning process more transparent, as the generated <think> tags reveal the steps taken to reach a conclusion.
Model Distillation: Teaching Smaller Models
Distillation is like having a master chef (a large, powerful AI model) teach an apprentice (a smaller model). The apprentice learns to mimic the master’s skills, becoming efficient and capable without needing all the master’s resources.
Model distillation enables DeepSeek-R1 to enhance the reasoning abilities of smaller variants within the Qwen and Llama series. This is done via supervised fine-tuning (SFT) on a dataset of high-quality samples generated by DeepSeek-R1. This method proves more effective than RL for improving reasoning in these smaller models, boosting performance without increasing size.
Test-Time Scaling: Thinking on the Fly
Imagine a master chess player who normally has 30 seconds to make each move. When given 2 minutes instead, they don’t suddenly learn new strategies, but they can think more deeply about possible moves, consider alternatives, and often make better decisions. This is analogous to test-time scaling in AI.
Test-time scaling allows AI models to utilize additional computational resources during inference without modifying their trained parameters. DeepSeek-R1-Zero exemplifies this approach by allocating extra resources for deeper reasoning when tackling complex problems.
DeepSeek researchers documented a fascinating phenomenon they call the “Aha Moment.” This refers to the emergent capability of DeepSeek-R1-Zero, when provided with additional computational resources at inference time, to exhibit sophisticated behavior, including self-reflection and the exploration of alternative solution paths. As shown in the table below, an intermediate version of the model demonstrated this behavior while solving an equation. The model initially pursued one approach, then paused, reassessed its strategy, and proceeded with a revised solution.

source : DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via
Reinforcement Learning
This emergent ability of DeepSeek-R1-Zero to dynamically adjust resources and re-evaluate its approach, achieved through RL, significantly boosts its performance on complex reasoning tasks. DeepSeek-R1 further refines this capability, leveraging test-time scaling for enhanced reasoning.
Conclusion
DeepSeek’s approach, exemplified by models like DeepSeek-R1, combines several powerful techniques to achieve both high performance and broader accessibility. These include Mixture of Experts (MoE) for efficient processing, reinforcement learning (RL) for autonomous learning and reasoning, model distillation to transfer reasoning capabilities to smaller models, Chain-of-Thought (CoT) for structured reasoning, and test-time scaling for refining reasoning during inference. This sophisticated combination of techniques, particularly the innovative use of RL, allows DeepSeek to push the boundaries of what’s possible with AI.
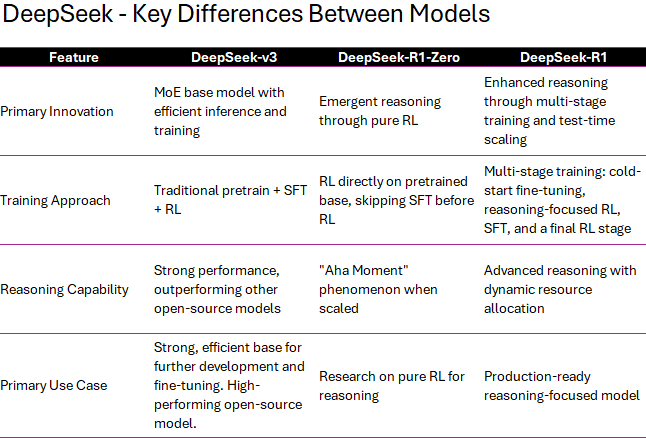
DeepSeek-V3, R1-Zero, and R1: A Comparison
References
[1] DeepSeek-AI et al., “DeepSeek-V3 Technical Report,” arXiv:2412.19437v2 . Submitted Dec. 27, 2024, Revised Feb. 18, 2025. Accessed on: Mar. 7, 2025. [Online]. Available: https://doi.org/10.48550/arXiv.2412.19437
[2] DeepSeek-AI et al., “DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning,” arXiv:2501.12948v1. Submitted Jan. 22, 2025. Accessed on: Mar. 7, 2025. [Online]. Available: https://doi.org/10.48550/arXiv.2501.12948
This post was researched , written, and illustrated with the assistance of various AI-based tools.

Leave a comment